Visualisierung des Wissens für relevante Stakeholder
Während Ontologien und darauf aufbauende Wissensgraphen maschinenverständlich sind, so sind sie in ihrer Rohform für menschliche Nutzer eher unzugänglich. Das macht es notwendig, die darin enthaltenen Informationen so aufzubereiten, dass sie auch für verschiedene menschliche Zielgruppen übersichtlich und strukturiert dargestellt werden können. Im einfachsten Falle werden, wie bei Wikidata, alle Bestandteile des Wissensgraphen inklusive ihrer jeweiligen Eigenschaften und Verknüpfungen in tabellarischer Textform angezeigt. Diese Aufbereitung ist aber für die meisten Zielgruppen und Aufgabenstellungen wenig geeignet. Vielmehr braucht es hier eine Darstellung, die sich in der jeweiligen Sicht auf die vorliegenden Informationen orientiert. Im Idealfall können so, auf einer einheitlichen Basis, jeder Zielgruppe die Daten so präsentiert werden, dass wesentliche Aspekte mühelos erfasst werden können und eine intuitive Benutzerführung ermöglicht wird.
Im Rahmen von KollOM-FIT wurde mit der Implementierung einer ersten solchen Darstellung begonnen. Diese sollte sich insb. an Entwickelnde richten, die auf Basis der bereitgestellten Informationen Anwendungen für den entsprechenden Bereich der öffentlichen Verwaltung erstellen wollen. Neben diesem Fokus wurden folgende Grundsätze für die Darstellung festgelegt:
- Prozessorientierung. Die primäre Darstellung orientiert sich am Prozessablauf der jeweiligen Leistung. Hier soll Nutzenden eine Visualisierung angeboten werden, die sich an gängigen Prozessdiagrammen, wie BPMN oder Datenflussdiagrammen, orientiert.
- Overview first, details on demand. In Anlehnung an Ben Shneidermans Mantra sollen Nutzende nicht mit einer Vielzahl an Informationen überfordert werden, sondern zuerst einen Überblick erhalten, zu dem sie dann bei Bedarf entsprechende Detailinformationen erreichen können.
- Weitere zentrale Komponenten. Über Prozesse hinaus enthält der Wissensgraph weitere zentrale Elemente (bspw. rechtliche Normen oder beteiligte Akteure). Diese sollen eigene dedizierte Übersichtsseiten erhalten, um die jeweiligen Eigenschaften darzustellen.
- Verknüpfungen. An jeder Stelle der Anwendung, bei der ein Verweis auf andere Elemente dargestellt wird, sollte es für Nutzende direkt möglich sein, auf die entsprechende Übersichtsseite zu gelangen.
- Wiedererkennung. Instanzen derselben Klasse von Elementen sollen über die ganze Anwendung hinweg eine einheitliche Darstellung haben. Das soll es Nutzenden ermöglichen, gleiche bzw. ähnliche Elemente schnell und einfach wiederzuerkennen.
Auf Basis dieser Grundsätze wurde eine erste Anwendung erstellt. Als zentrale Komponenten wurden (bislang) definiert: Leistungen und ihre zugrunde liegenden Prozesse, rechtliche Normen, Akteure sowie assoziierte Ressourcen wie bspw. verwendete Software oder Datenfelder. Jedem Typ dieser Komponenten wurde eine Farbe zugeordnet, die eine Wiedererkennung auf den verschiedenen Seiten ermöglichen soll. Weiterhin wurde für jeden Komponententyp eine Übersichtsseite erstellt, die die jeweiligen Einträge auflistet und (anhand des Namens) durchsuchbar macht. Die Übersichtsseiten für die einzelnen Komponenten sind unten anhand beispielhafter Screenshots dokumentiert.
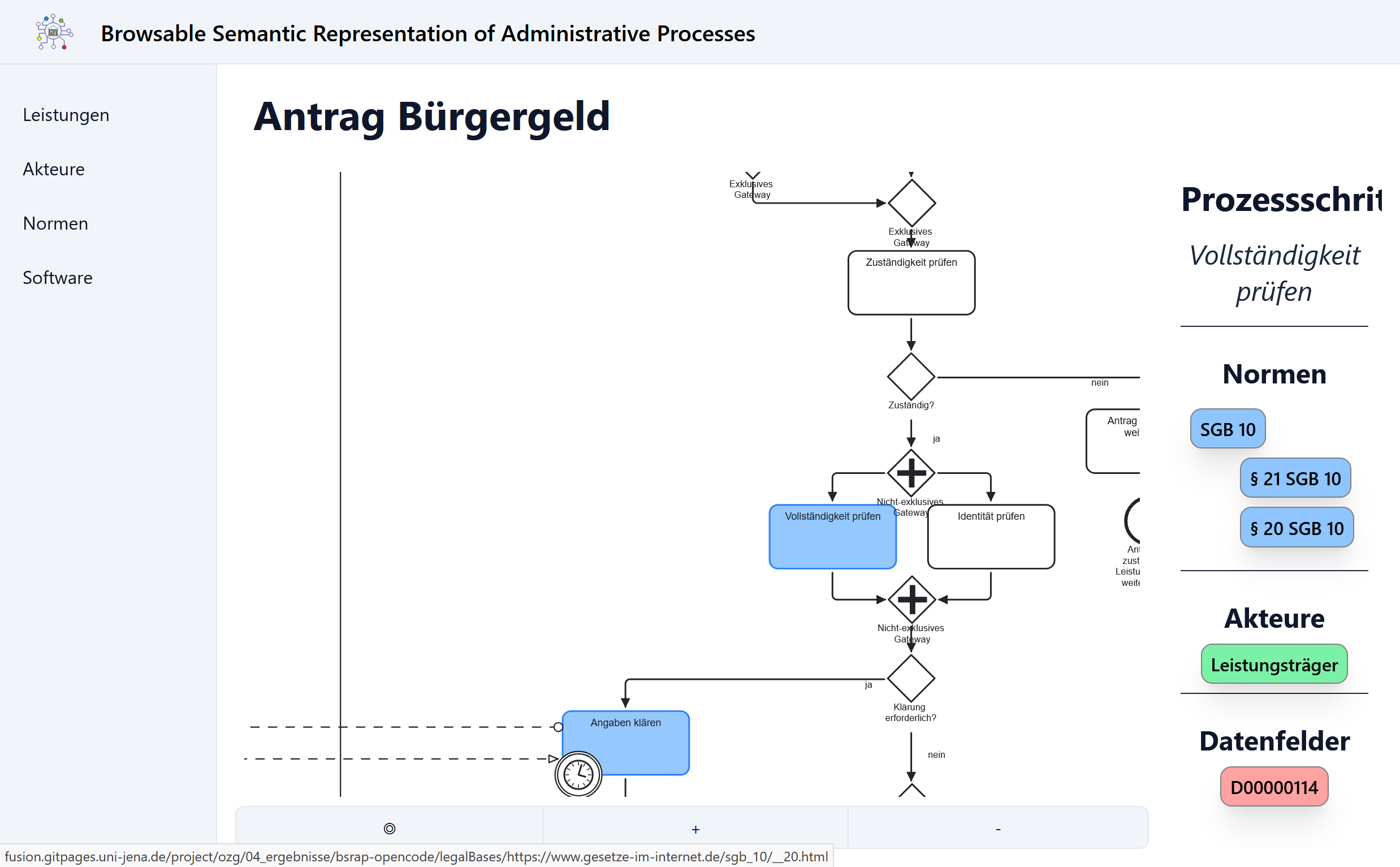
Eine herausragende Position nimmt hierbei die Übersichtsseite einer Leistung ein. Anfangs stellt diese den Prozessablauf der Leistung in Form eines BPMN-Diagramms dar und enthält weiterhin alle Informationen, die für den Prozess als Ganzes relevant sind. Nutzende können nun einzelne Prozessschritte auswählen und erhalten damit Zugang zu den Details für den konkreten, ausgewählten Schritt. Ebenso lassen sich aus den Zusatzinformationen heraus einzelne Elemente auswählen, wonach dann im Prozessdiagramm alle davon betroffenen Prozessschritte hervorgehoben werden. Daneben bieten alle dargestellten Komponenten eine Verknüpfung zu den jeweiligen Übersichtsseiten und damit zu allen dazu bekannten Details.
Die Anwendung ist öffentlich hier erreichbar. Eine technische Dokumentation findet man hier.
Screenshots